When attempting to backtest their strategies, traders may experience common pitfalls that skew their data, forgoing potential gains or experiencing losses. To avoid skewed data, backtests must preemptively adjust for non-material data points which skew the larger data set.
Expected Value
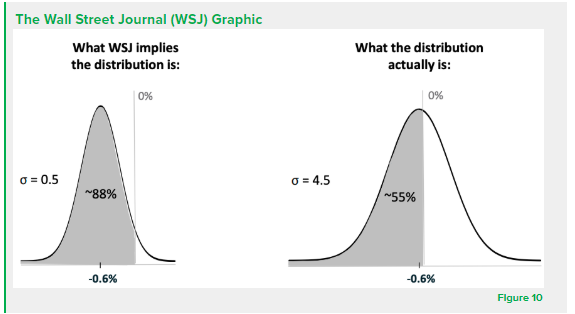
The expected value should not be the sole variable used to describe a set of data. Instead, traders should also focus on volatility, skew, and max drawdown. An article written by The Wall Street Journal analyzed the average monthly percentage change for the Dow Jones Industrial Average and found that the index has the lowest average return in the month of September. Although the article insinuates that traders should short the index during September, the distribution in Figure 10 demonstrates that the index performs only marginally worse. The dichotomy between the Wall Street Journal’s implication and the true value of the distribution reveals the futility of only considering one dimension of a data set. Backtesting models must take into account all metrics including standard deviation and the Sharpe ratio. Some backtesters allow traders to visualize distributions, which would mitigate the aforementioned scenario and potential losses.
Survivorship Bias
Survivorship bias occurs when data from failed companies are excluded from a backtest. Over time, companies with consistent access to investor capital (debt or equity) are likely to stay afloat, whereas companies without such access are more prone to failure. Backtesting with successful companies may positively skew results and artificially inflate returns. For example, the S&P is continuously rebalanced. The companies that comprised the S&P in 2005 are not the same companies that are in the S&P today. In addition, mutual funds are also rebalanced over time because some companies experience poor performance. In order to mitigate survivorship bias when backtesting the S&P or mutual funds, the backtesting program will have to account for changes in all companies that once existed in the funds. In doing so, traders will conduct a holistic analysis of the instruments and limit survivorship bias.
Correlation vs. Causation
Correlation does not imply causation. Causation can only be established through perfect isolation of relevant variables. Accordingly, economic/financial analysis precludes determination of causation due to the impossibility of perfectly isolating variables. Assuming that correlation implies causation can lead to negative returns for traders. An example of a false correlation can be found in the Rolling Stone Magazine article that plotted rock music quality alongside the United States oil production (Figure 11). The two variables appear to be correlated
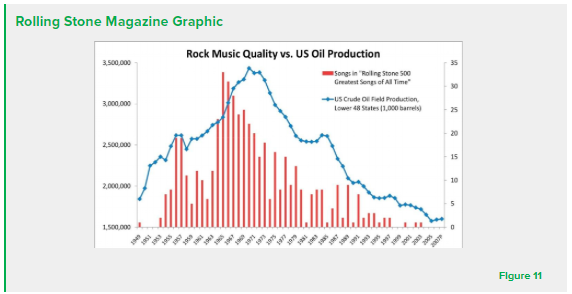
with each other, but the confounding variables reveal that there is no direct relationship between the two variables. Ultimately, backtesting software must undergo significant testing to verify statistical significance of apparent correlations.
Unrepresentative Time Period
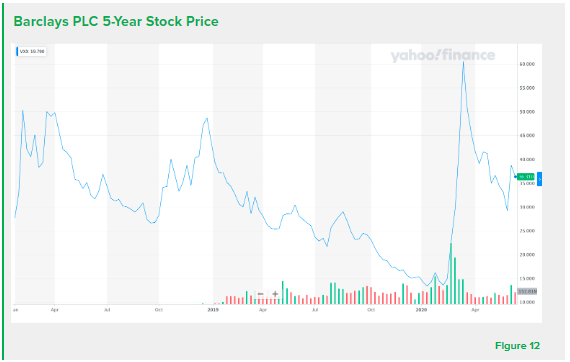
Backtesting must be completed on data from a time period that is reflective of the current environment. Additionally, large sample sizes are required to be representative of the environment. For instance, if data is primarily selected from recessionary periods, results will not represent general market conditions. Conversely, data which is primarily selected from periods of economic growth may positively skew results. For example, Figure 12 shows the Barclays PLC 5-Year Stock Price. If a backtester implemented a strategy using a sample of data points from February to March of 2020, the strategy would be falsely understood as incredibly efficient. However, data points before February of 2020 are volatile and decline in price. Backtesting programs can bypass selecting an unrepresentative time period by collecting a simple random sample of points. A simple random sample limits inherent bias from the selection process and ensures that the strategy is performed on a representative sample of points. The strategy will then be applied an ample amount of times on many different samples of data to determine its effectiveness.
Continue to the next part of our backtester series here.